Facebook Archive Analysis
A data pipeline that processes Facebook's personal data archive to extract insights about messaging patterns, friend connections, and communication habits using Python and SQL.
Technologies Used
Context
Most social media platforms, including Facebook, allow you to download your data archive. All your messages, friend connections, likes, comments - Facebook exports it all as JSON files.
I got curious: how do my stats actually look? What are my communication patterns?
Instead of just scrolling through old chats, I decided to build a proper data pipeline to analyze this systematically.
Solution
The project turned into a complete ETL pipeline (although run on demand, not on schedule) - from raw JSON files to a queryable SQLite database with visualizations.
Processing the Archive
Facebook exports your data as hundreds of JSON files scattered across folders. My pipeline:
- Recursively finds and processes all message files (handled 255+ files in about 13 seconds)
- Deals with Facebook’s weird encoding choices (Latin1 → UTF-8 conversion)
- Enriches the data with derived fields - extracting year, day, hour from timestamps, classifying sent vs. received messages
Building the Database
Everything gets loaded into a SQLite database with proper tables for messages and friend connections. This makes it easy to run SQL queries and explore the data however you want.
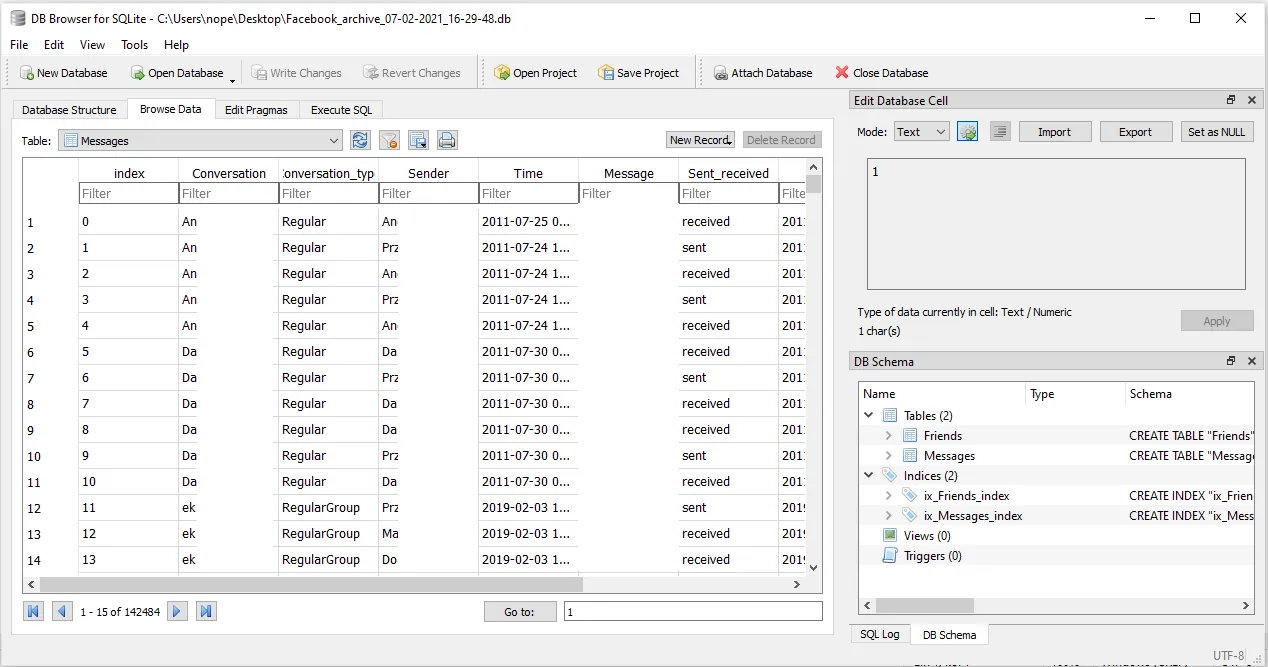
The data can be explored using Python, but also queried directly using a database UI tool like DB Browser for SQLite.
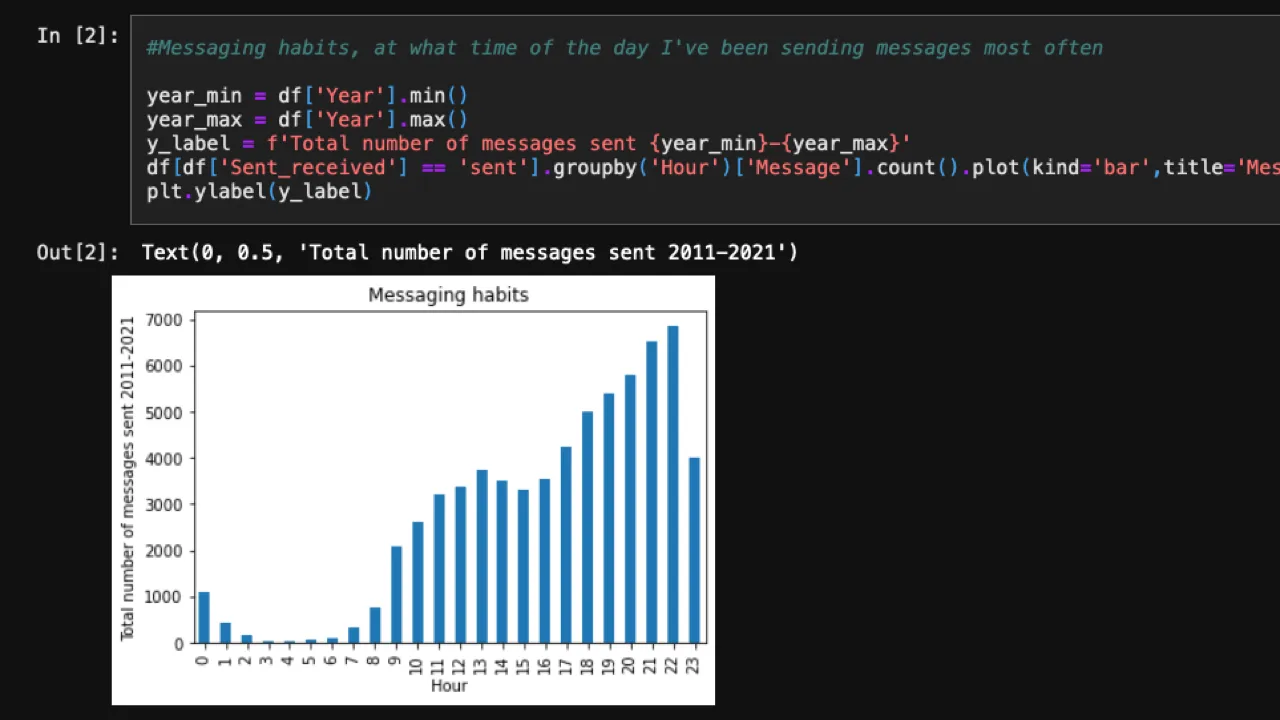
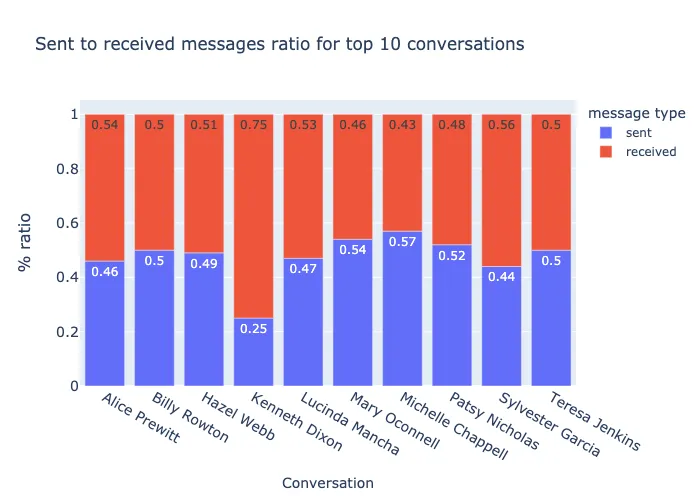
What I Discovered
Some interesting findings from analyzing my own data:
- 5.6M+ words across all conversations (that’s a lot of chatting over the years)
- 42.3% of my Facebook friends had actual message history with me
- Clear patterns in when I’m most active - time-of-day communication habits
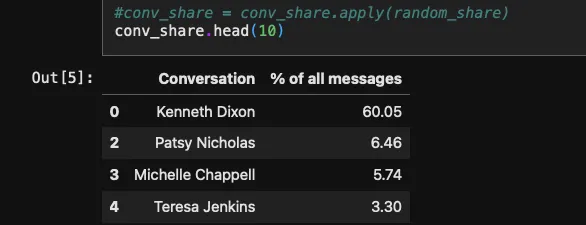
- Some conversations were pretty one-sided (either them or me doing most of the talking)
I also generated a word cloud from all messages to see vocabulary patterns (though it needs additional filtering to be truly meaningful).

Privacy Considerations
Since this involves personal data and I wanted to share the project publicly, I built in anonymization - all names are replaced with randomly generated ones before any visualizations are shared. Some numbers are also randomized.
Real-world Application
This is basically a data engineering project applied to personal data:
- ETL pipeline - extracting from messy source files, transforming, loading into a database
- Encoding issues - a classic real-world data problem
- Multiple analysis approaches - both pandas and SQL
- Visualization - using the right tool for each use case
The same techniques apply to any JSON-based data source - API responses, log files, export archives from various platforms.
Professional Takeaways
- Handling messy real-world data - encoding issues, inconsistent structures, missing fields
- Building proper pipelines - not just notebooks, but reusable code that processes data consistently
- SQL and Python together - using each where it makes sense
- Privacy awareness - thinking about anonymization when working with personal data. This is especially relevant in the LLM era, where we should be cautious about what we share not only with people, but with AI as well