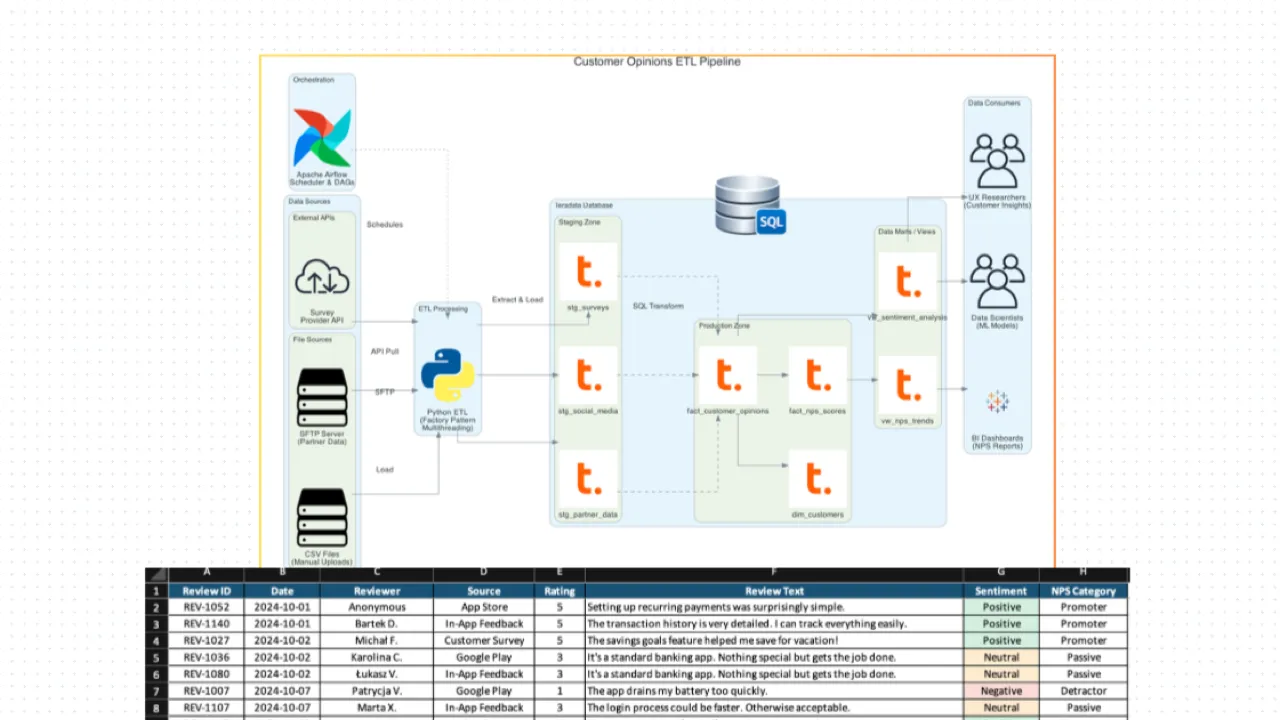
Customer Opinions ETL Pipeline
Company:
![]() Santander Bank Poland
Santander Bank Poland
A production ETL pipeline processing customer feedback data from multiple sources, enabling data scientists and researchers to analyze sentiment, measure NPS, and understand customer experience.
Technologies Used
Due to NDAs, no real screenshots or code can be shown for corporate projects. Instead, mockup scripts were created to generate images resembling the original projects.
Problem Definition
You write a comment about your bank somewhere on the internet, or you complete a survey, and then you might wonder - will anybody care?
And the answer is: Yes, pretty much.
But on the opposite side of the fence, from a technical standpoint, it’s not easy for any company to thoroughly track what customers really think about their services. Different surveys, social media posts and comments, feedback forms - all this data might be scattered across different platforms, systems and providers.
In my final months at Santander, I joined a team that was tackling exactly this challenge. The goal was to collect customer opinions from various sources, process them, and make them available for analysis - so data scientists could run sentiment models, UX specialists could measure experience, and the business could track NPS scores.
Solution
This was a production ETL pipeline, already established when I joined. The data came from multiple channels:
- Customer surveys
- API integrations with external providers
- File-based data from various sources
- Social media mentions
Everything was Python-based, with SQL transformations for data preparation, all deployed and scheduled in Airflow.
My Contributions
Performance optimization - improving existing processes and refactoring code that had accumulated technical debt over time.
New data source integrations - implementing connections to additional providers, following the established patterns, but also requiring distinct solutions (like connecting to a new API, or extending database structures to accommodate new data).
Documentation - the pipeline had grown organically and documentation was lacking. I worked on filling those gaps and helping onboard new team members.
The Different Challenge
Unlike most of my projects where I built things from scratch, here I had to adapt to someone else’s codebase and way of thinking - which I personally found overengineered in places. Different coding style, different patterns, decisions I would have made differently. But this is the reality of software engineering - not every project is greenfield.
Impact
The data we processed was genuinely valuable for the bank:
- Customer satisfaction insights - understanding what people actually think
- Data-driven decisions - supporting product and service improvements
- NPS tracking - measuring the key metric over time
And by having this centralized pipeline and single point of truth for all customer opinions, we have saved many hours of work from other teams on data processing tasks, instead enabling them to focus on their core work like research or modeling.
Beyond the technical work, this role involved a lot of stakeholder management - regular communication with business teams, translating their needs into code, coordinating with external data providers, and navigating GDPR/data privacy requirements with legal teams.
Professional Takeaways
- Working within an established technical team - before I would quite often work within more business-focused teams, being the most technical person there, while here I was working with technical experts more experienced than me, so I had to adapt to existing codebases and team dynamics, but I could also extensively learn from them
- Production mindset - maintaining critical infrastructure that others depend on, where failures have real consequences
- This project felt like a full-circle moment - proper data engineering, from collection through processing to enabling insights. It reinforced that data pipelines are the backbone that makes analytics, ML, and business intelligence possible.